<< Previous Page | Next Page >>
Fetch Part 4: Autonomous Pick Up
Now that we can identify the toy, we'll write a script to automatically pick it up.
Create a new file called fetch.py in your ~/fetch folder. Paste or download the following:
- Note: If you download the file, rename it to
fetch.py
import argparse
import sys
import time
import numpy as np
import cv2
import math
import bosdyn.client
import bosdyn.client.util
from bosdyn.client.robot_state import RobotStateClient
from bosdyn.client.robot_command import RobotCommandClient, RobotCommandBuilder, block_until_arm_arrives
from bosdyn.api import geometry_pb2
from bosdyn.client.lease import LeaseClient, LeaseKeepAlive
from bosdyn.api import image_pb2
from bosdyn.client.network_compute_bridge_client import NetworkComputeBridgeClient
from bosdyn.api import network_compute_bridge_pb2
from google.protobuf import wrappers_pb2
from bosdyn.client.manipulation_api_client import ManipulationApiClient
from bosdyn.api import manipulation_api_pb2
from bosdyn.api import basic_command_pb2
from bosdyn.client import frame_helpers
from bosdyn.client import math_helpers
kImageSources = [
'frontleft_fisheye_image', 'frontright_fisheye_image',
'left_fisheye_image', 'right_fisheye_image', 'back_fisheye_image'
]
Import the desired libraries and define a constant with the image sources we'll use.
def get_obj_and_img(network_compute_client, server, model, confidence,
image_sources, label):
for source in image_sources:
# Build a network compute request for this image source.
image_source_and_service = network_compute_bridge_pb2.ImageSourceAndService(
image_source=source)
# Input data:
# model name
# minimum confidence (between 0 and 1)
# if we should automatically rotate the image
input_data = network_compute_bridge_pb2.NetworkComputeInputData(
image_source_and_service=image_source_and_service,
model_name=model,
min_confidence=confidence,
rotate_image=network_compute_bridge_pb2.NetworkComputeInputData.
ROTATE_IMAGE_ALIGN_HORIZONTAL)
# Server data: the service name
server_data = network_compute_bridge_pb2.NetworkComputeServerConfiguration(
service_name=server)
# Pack and send the request.
process_img_req = network_compute_bridge_pb2.NetworkComputeRequest(
input_data=input_data, server_config=server_data)
try:
resp = network_compute_client.network_compute_bridge_command(process_img_req)
except ExternalServerError:
# This sometimes happens if the NCB is unreachable due to intermittent wifi failures.
print('Error connecting to network compute bridge. This may be temporary.')
return None, None, None
Make a function that iterates over each image source and issues a NetworkComputeRequest for each image source.
best_obj = None
highest_conf = 0.0
best_vision_tform_obj = None
img = get_bounding_box_image(resp)
image_full = resp.image_response
# Show the image
cv2.imshow("Fetch", img)
cv2.waitKey(15)
Call the function that draws bounding boxes on the image (see below) and show the image to the user.
if len(resp.object_in_image) > 0:
for obj in resp.object_in_image:
# Get the label
obj_label = obj.name.split('_label_')[-1]
if obj_label != label:
continue
conf_msg = wrappers_pb2.FloatValue()
obj.additional_properties.Unpack(conf_msg)
conf = conf_msg.value
Unpack the confidence value for each object in the image.
try:
vision_tform_obj = frame_helpers.get_a_tform_b(
obj.transforms_snapshot,
frame_helpers.VISION_FRAME_NAME,
obj.image_properties.frame_name_image_coordinates)
except bosdyn.client.frame_helpers.ValidateFrameTreeError:
# No depth data available.
vision_tform_obj = None
if conf > highest_conf and vision_tform_obj is not None:
highest_conf = conf
best_obj = obj
best_vision_tform_obj = vision_tform_obj
if best_obj is not None:
return best_obj, image_full, best_vision_tform_obj
return None, None, None
- The robot automatically computes the position of the object by correlating its depth camera with the pixels in the bounding box.
- Note: The depth cameras' field of views are smaller than the grayscale cameras, so some objects will not have a position computed.
- Compare the value to the best confidence we've seen in this image.
- Return the object with the highest confidence that has position data, or nothing if there are no objects.
def get_bounding_box_image(response):
dtype = np.uint8
img = np.fromstring(response.image_response.shot.image.data, dtype=dtype)
if response.image_response.shot.image.format == image_pb2.Image.FORMAT_RAW:
img = img.reshape(response.image_response.shot.image.rows,
response.image_response.shot.image.cols)
else:
img = cv2.imdecode(img, -1)
# Convert to BGR so we can draw colors
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
# Draw bounding boxes in the image for all the detections.
for obj in response.object_in_image:
conf_msg = wrappers_pb2.FloatValue()
obj.additional_properties.Unpack(conf_msg)
confidence = conf_msg.value
polygon = []
min_x = float('inf')
min_y = float('inf')
for v in obj.image_properties.coordinates.vertexes:
polygon.append([v.x, v.y])
min_x = min(min_x, v.x)
min_y = min(min_y, v.y)
polygon = np.array(polygon, np.int32)
polygon = polygon.reshape((-1, 1, 2))
cv2.polylines(img, [polygon], True, (0, 255, 0), 2)
caption = "{} {:.3f}".format(obj.name, confidence)
cv2.putText(img, caption, (int(min_x), int(min_y)),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return img
The get_bounding_box_image function returns an image with bounding boxes drawn on top.
- Unpack the image from the proto.
- Convert to color so we can draw green boxes on top of the gray-scale images.
- For each detected object:
- Draw a line between each polygon corner.
- Draw a caption with the object's name and confidence value.
def find_center_px(polygon):
min_x = math.inf
min_y = math.inf
max_x = -math.inf
max_y = -math.inf
for vert in polygon.vertexes:
if vert.x < min_x:
min_x = vert.x
if vert.y < min_y:
min_y = vert.y
if vert.x > max_x:
max_x = vert.x
if vert.y > max_y:
max_y = vert.y
x = math.fabs(max_x - min_x) / 2.0 + min_x
y = math.fabs(max_y - min_y) / 2.0 + min_y
return (x, y)
Function to find the approximate center of a polygon by taking the axis-aligned bounding box's center. While imperfect, it meets our needs.
def block_for_trajectory_cmd(command_client, cmd_id, timeout_sec=None, verbose=False):
"""Helper that blocks until a trajectory command reaches STATUS_AT_GOAL or a timeout is
exceeded.
Args:
command_client: robot command client, used to request feedback
cmd_id: command ID returned by the robot when the trajectory command was sent
timeout_sec: optional number of seconds after which we'll return no matter what the
robot's state is.
verbose: if we should print state at 10 Hz.
Returns:
True if reaches STATUS_AT_GOAL, False otherwise.
"""
start_time = time.time()
if timeout_sec is not None:
end_time = start_time + timeout_sec
now = time.time()
while timeout_sec is None or now < end_time:
feedback_resp = command_client.robot_command_feedback(cmd_id)
current_state = feedback_resp.feedback.mobility_feedback.se2_trajectory_feedback.status
if verbose:
current_state_str = basic_command_pb2.SE2TrajectoryCommand.Feedback.Status.Name(current_state)
current_time = time.time()
print('Walking: ({time:.1f} sec): {state}'.format(
time=current_time - start_time, state=current_state_str),
end=' \r')
if current_state == basic_command_pb2.SE2TrajectoryCommand.Feedback.STATUS_AT_GOAL:
return True
time.sleep(0.1)
now = time.time()
if verbose:
print('block_for_trajectory_cmd: timeout exceeded.')
return False
Poll the robot for feedback and return when the robot reports STATUS_AT_GOAL.
def main(argv):
parser = argparse.ArgumentParser()
bosdyn.client.util.add_base_arguments(parser)
parser.add_argument(
'-s',
'--ml-service',
help='Service name of external machine learning server.',
required=True)
parser.add_argument('-m',
'--model',
help='Model name running on the external server.',
required=True)
parser.add_argument(
'-p',
'--person-model',
help='Person detection model name running on the external server.')
parser.add_argument('-c',
'--confidence-dogtoy',
help='Minimum confidence to return an object for the dogtoy (0.0 to 1.0)',
default=0.5,
type=float)
parser.add_argument('-e',
'--confidence-person',
help='Minimum confidence for person detection (0.0 to 1.0)',
default=0.6,
type=float)
options = parser.parse_args(argv)
cv2.namedWindow("Fetch")
cv2.waitKey(500)
Set up arguments and tell OpenCV to create an output window.
sdk = bosdyn.client.create_standard_sdk('SpotFetchClient')
sdk.register_service_client(NetworkComputeBridgeClient)
robot = sdk.create_robot(options.hostname)
bosdyn.client.util.authenticate(robot)
# Time sync is necessary so that time-based filter requests can be converted
robot.time_sync.wait_for_sync()
network_compute_client = robot.ensure_client(
NetworkComputeBridgeClient.default_service_name)
robot_state_client = robot.ensure_client(
RobotStateClient.default_service_name)
command_client = robot.ensure_client(
RobotCommandClient.default_service_name)
lease_client = robot.ensure_client(LeaseClient.default_service_name)
manipulation_api_client = robot.ensure_client(
ManipulationApiClient.default_service_name)
Below is the standard setup for a Spot API client. Note the manipulation_api_client is included so the arm can be used.
# This script assumes the robot is already standing via the tablet. We'll take over from the
# tablet.
lease_client.take()
Now we take over control from the tablet.
- This is a useful way to run quick tests, especially where it is difficult to align the robot correctly.
- Note: We used this technique to get all the robots in position for jump roping before starting the behavior.
with bosdyn.client.lease.LeaseKeepAlive(lease_client):
# Store the position of the hand at the last toy drop point.
vision_tform_hand_at_drop = None
while True:
holding_toy = False
while not holding_toy:
# Capture an image and run ML on it.
dogtoy, image, vision_tform_dogtoy = get_obj_and_img(
network_compute_client, options.ml_service, options.model,
options.confidence_dogtoy, kImageSources, 'dogtoy')
if dogtoy is None:
# Didn't find anything, keep searching.
continue
- Set up a lease keep-alive and start a loop.
- Search for a dog-toy until one is found.
# If we have already dropped the toy off, make sure it has moved a sufficient amount before
# picking it up again
if vision_tform_hand_at_drop is not None and pose_dist(
vision_tform_hand_at_drop, vision_tform_dogtoy) < 0.5:
print('Found dogtoy, but it hasn\'t moved. Waiting...')
time.sleep(1)
continue
After the dog-toy has been dropped off, loop back and wait for the person to throw it again.
print('Found dogtoy...')
# Got a dogtoy. Request pick up.
# Stow the arm in case it is deployed
stow_cmd = RobotCommandBuilder.arm_stow_command()
command_client.robot_command(stow_cmd)
# NOTE: we'll enable this code in Part 5, when we understand it.
# -------------------------
# # Walk to the object.
# walk_rt_vision, heading_rt_vision = compute_stand_location_and_yaw(
# vision_tform_dogtoy, robot_state_client, distance_margin=1.0)
# se2_pose = geometry_pb2.SE2Pose(
# position=geometry_pb2.Vec2(x=walk_rt_vision[0], y=walk_rt_vision[1]),
# angle=heading_rt_vision)
# move_cmd = RobotCommandBuilder.synchro_se2_trajectory_command(
# se2_pose,
# frame_name=frame_helpers.VISION_FRAME_NAME,
# params=get_walking_params(0.5, 0.5))
# end_time = 5.0
# cmd_id = command_client.robot_command(command=move_cmd,
# end_time_secs=time.time() +
# end_time)
# # Wait until the robot reports that it is at the goal.
# block_for_trajectory_cmd(command_client, cmd_id, timeout_sec=5, verbose=True)
# -------------------------
Right now, we aren't going to worry about walking longer distances, but in the next section we'll want to do that. Don't worry about this code now and we'll enable it in Part 5.
# The ML result is a bounding box. Find the center.
(center_px_x,
center_px_y) = find_center_px(dogtoy.image_properties.coordinates)
# Request Pick Up on that pixel.
pick_vec = geometry_pb2.Vec2(x=center_px_x, y=center_px_y)
grasp = manipulation_api_pb2.PickObjectInImage(
pixel_xy=pick_vec,
transforms_snapshot_for_camera=image.shot.transforms_snapshot,
frame_name_image_sensor=image.shot.frame_name_image_sensor,
camera_model=image.source.pinhole)
# We can specify where in the gripper we want to grasp. About halfway is generally good for
# small objects like this. For a bigger object like a shoe, 0 is better (use the entire
# gripper)
grasp.grasp_params.grasp_palm_to_fingertip = 0.6
The main Pick Up request:
- Find the center of the bounding box using our function above.
- Build the
PickObjectInImagerequest with: xandypixel locationtransforms_snapshotfrom the image (data about where the camera was when the picture was taken)- Name of the image sensor's frame
- Calibration data for the camera
- Set the
grasp_palm_to_fingertipparameter. This selects where in the hand the dog-toy will be grasped (think the gripper's palm vs. its fingertip).
# Tell the grasping system that we want a top-down grasp.
# Add a constraint that requests that the x-axis of the gripper is pointing in the
# negative-z direction in the vision frame.
# The axis on the gripper is the x-axis.
axis_on_gripper_ewrt_gripper = geometry_pb2.Vec3(x=1, y=0, z=0)
# The axis in the vision frame is the negative z-axis
axis_to_align_with_ewrt_vision = geometry_pb2.Vec3(x=0, y=0, z=-1)
# Add the vector constraint to our proto.
constraint = grasp.grasp_params.allowable_orientation.add()
constraint.vector_alignment_with_tolerance.axis_on_gripper_ewrt_gripper.CopyFrom(
axis_on_gripper_ewrt_gripper)
constraint.vector_alignment_with_tolerance.axis_to_align_with_ewrt_frame.CopyFrom(
axis_to_align_with_ewrt_vision)
# We'll take anything within about 15 degrees for top-down or horizontal grasps.
constraint.vector_alignment_with_tolerance.threshold_radians = 0.25
# Specify the frame we're using.
grasp.grasp_params.grasp_params_frame_name = frame_helpers.VISION_FRAME_NAME
Tell the grasping system that we will only accept a top-down grasp.
- Specifying this parameter increases the robustness of the grasp. We'd rather the robot report that it can't find a grasp than succeed at grasping the wrong thing.
Let's break down how this works:
- The
vector_alignment_with_tolerancesystem takes a vector on the gripper and a vector in a frame. It promises that those two vectors will be within a tolerance (in rotation). - We want a "top-down" grasp, so we'll set the X-axis of the gripper to be pointed straight down
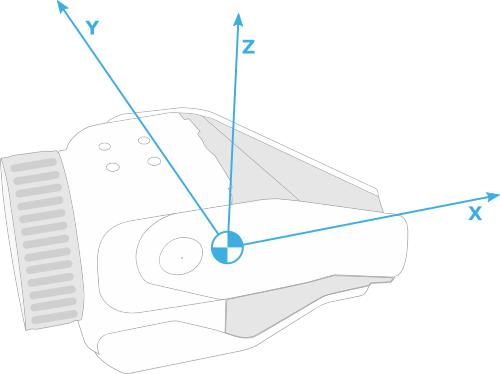
- X-axis of the gripper:
axis_on_gripper_ewrt_gripper = geometry_pb2.Vec3(x=1, y=0, z=0) - Straight down:
axis_to_align_with_ewrt_vision = geometry_pb2.Vec3(x=0, y=0, z=-1) - Set the tolerance to
0.25radians, or about 15 degrees. - Tell the robot we are expressing the second vector in the vision frame.
Time to command a grasp!
# Build the proto
grasp_request = manipulation_api_pb2.ManipulationApiRequest(
pick_object_in_image=grasp)
# Send the request
print('Sending grasp request...')
cmd_response = manipulation_api_client.manipulation_api_command(
manipulation_api_request=grasp_request)
- Send the request to the robot.
# Wait for the grasp to finish
grasp_done = False
failed = False
time_start = time.time()
while not grasp_done:
feedback_request = manipulation_api_pb2.ManipulationApiFeedbackRequest(
manipulation_cmd_id=cmd_response.manipulation_cmd_id)
# Send a request for feedback
response = manipulation_api_client.manipulation_api_feedback_command(
manipulation_api_feedback_request=feedback_request)
current_state = response.current_state
current_time = time.time() - time_start
print('Current state ({time:.1f} sec): {state}'.format(
time=current_time,
state=manipulation_api_pb2.ManipulationFeedbackState.Name(
current_state)),
end=' \r')
sys.stdout.flush()
failed_states = [manipulation_api_pb2.MANIP_STATE_GRASP_FAILED,
manipulation_api_pb2.MANIP_STATE_GRASP_PLANNING_NO_SOLUTION,
manipulation_api_pb2.MANIP_STATE_GRASP_FAILED_TO_RAYCAST_INTO_MAP,
manipulation_api_pb2.MANIP_STATE_GRASP_PLANNING_WAITING_DATA_AT_EDGE]
failed = current_state in failed_states
grasp_done = current_state == manipulation_api_pb2.MANIP_STATE_GRASP_SUCCEEDED or failed
time.sleep(0.1)
holding_toy = not failed
The grasp will take time to complete.
- Poll the robot until the grasp is finished.
- Print the status data.
- Note if the grasp failed or succeeded.
# Move the arm to a carry position.
print('')
print('Grasp finished, search for a person...')
carry_cmd = RobotCommandBuilder.arm_carry_command()
command_client.robot_command(carry_cmd)
# Wait for the carry command to finish
time.sleep(0.75)
After the grasp is complete, move the arm to a "carry" position. This moves the arm out of the way of the front cameras.
# For now, we'll just exit...
print('')
print('Done for now, returning control to tablet in 5 seconds...')
time.sleep(5.0)
break
For now, we'll just exit. Once we've successfully tested, we'll add person detection here. As the code exits the keep-alive context manager, the lease is returned.
if __name__ == '__main__':
if not main(sys.argv[1:]):
sys.exit(1)
Finish up with some python boilerplate.
Running Automatic Dog-Toy Grasping
For this, we'll keep running our network_compute_server.py in a separate terminal. Here's the diagram:
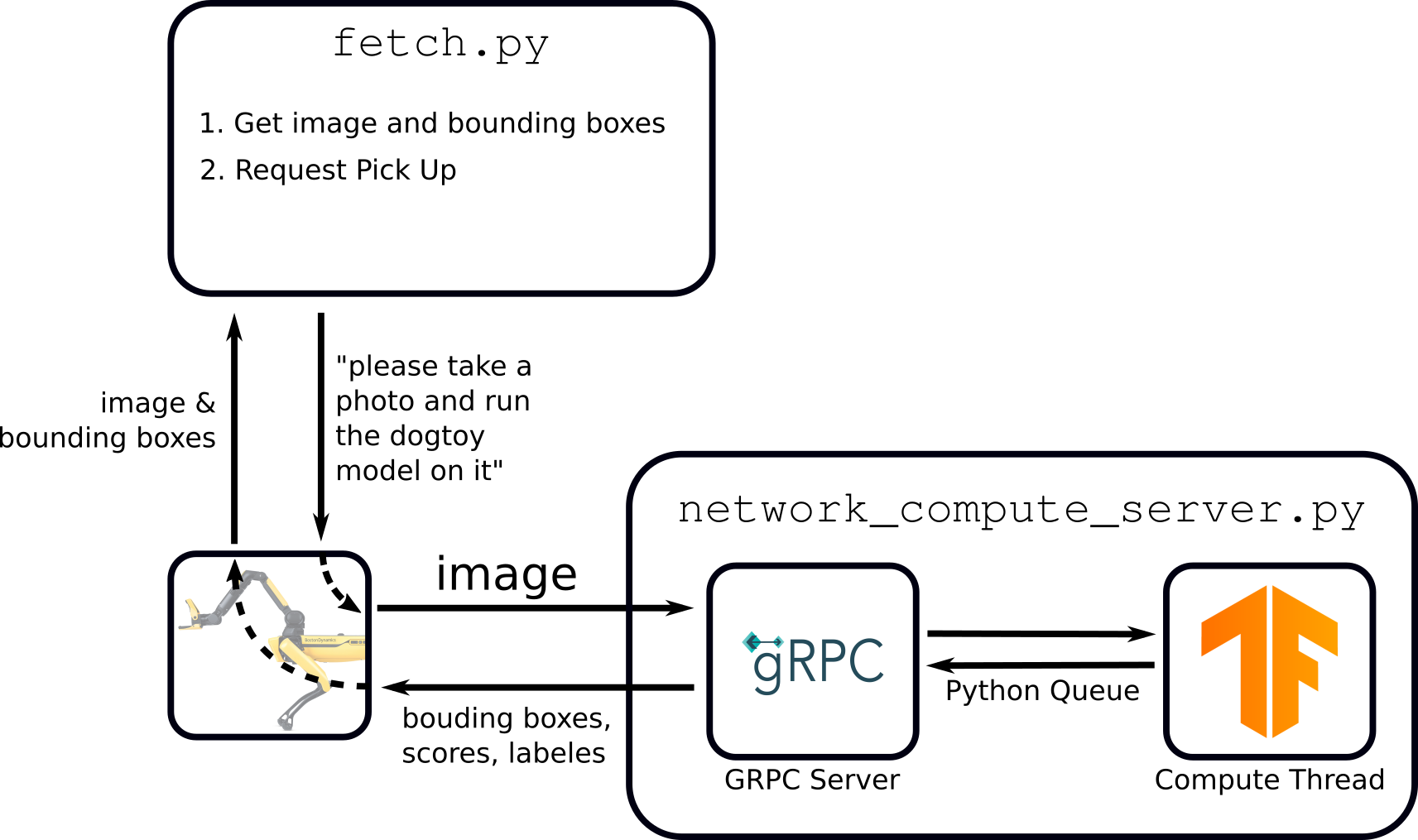
Notice that two scripts will be running. The advantage being that your ML model server doesn't care what you're doing with the results.
Start (or keep running) your network_compute_server.py
python3 network_compute_server.py -m dogtoy/exported-models/dogtoy-model/saved_model -l dogtoy/annotations/label_map.pbtxt 192.168.80.3
Run fetch.py
Our fetch script takes over from the tablet.
- Command Spot to Stand using the tablet.
- Place the dog-toy on the floor.
- Walk Spot near to the dog-toy.
While the robot is on and standing, in a new terminal:
python3 fetch.py -s fetch-server -m dogtoy-model 192.168.80.3
Upon success, your robot should autonomously find and pick up the dog-toy!
Troubleshooting
Not Finding the Dog-Toy
- At any time you can use the ML Model Viewer and make sure your model is still working.
fetch.pyuses the same code-path as the ML Model Viewer, so if that is working, this script should work.
Failing to Grasp
- Try changing
grasp.grasp_params.grasp_palm_to_fingertip = 0.5to0.0or1.0 - Use the tablet's Pick Up Object action and see if Spot can grasp the dog-toy using that method.
- Try running the arm_grasp API example and compare the results.
- If your dog-toy is a long rope, the center of your bounding boxes might be empty space. Try tying the rope so the center is always graspable.
Once you're happy with your autonomous picks, head over to Part 5 to start playing fetch!
Head over to Part 5: Detecting People and Playing Fetch >>
<< Previous Page | Next Page >>