About Orbit (formerly Scout)
Orbit is a collection of web services for site awareness, fleet management and data centralization deployed to an on-premise or cloud server. Learn more about the product and deployment here.
Orbit collects, organizes, and stores data from every mission and teleoperation session executed by a Spot fleet - this information is served to users through a programmatic Application Programming Interface (API) called the Orbit API.
Contents
WebViews
Orbit has the ability to embed external websites in the Orbit user interface, this is referred to as a WebView. Only sites that utilize HTTPS can be embedded into Orbit. For unverified TLS sites the user must first accept the privacy errors for that site before the site will show up correctly in the Orbit web view.
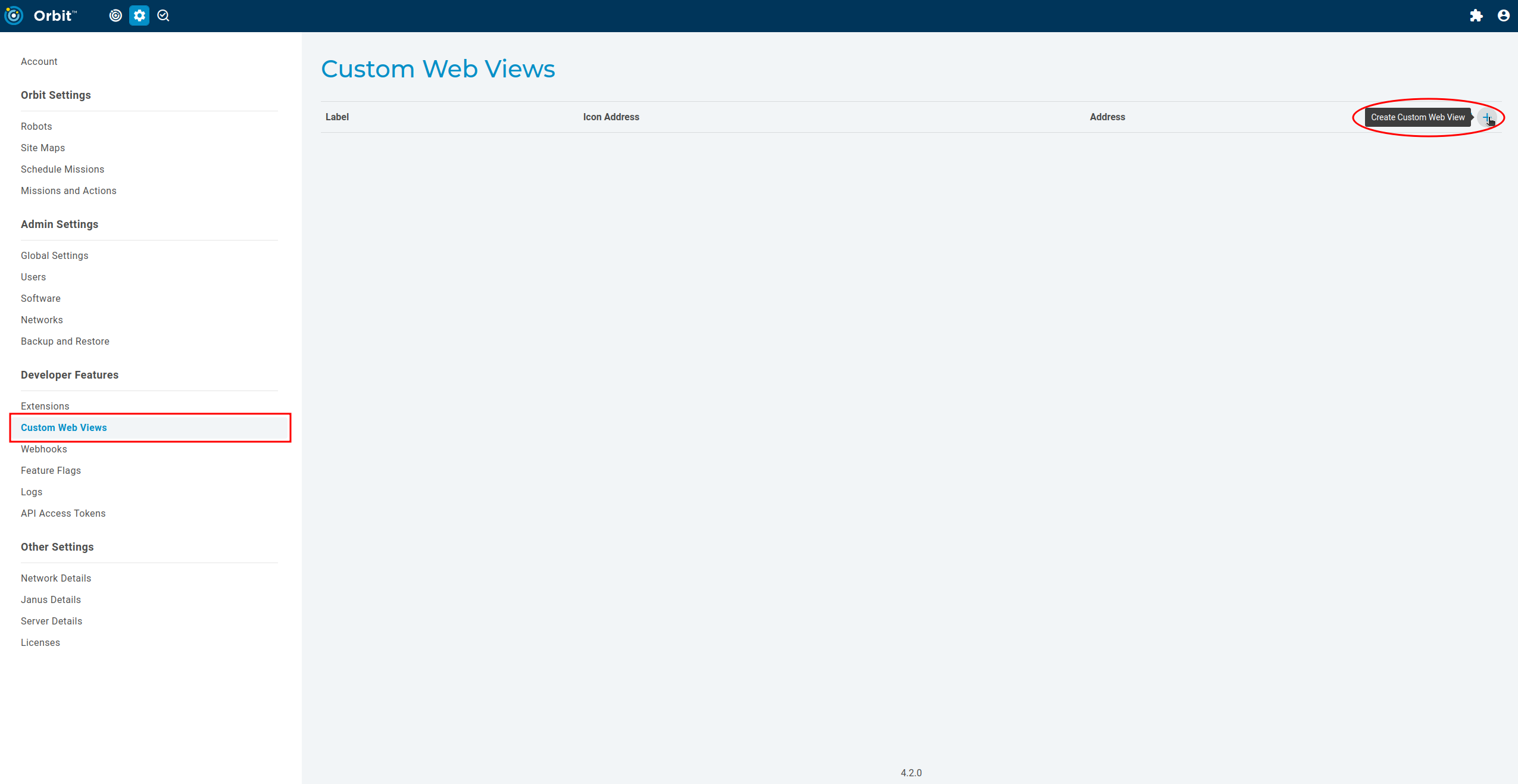
To add a website as a web view first navigate to “Custom Web Views” in the Orbit settings page. Click the plus icon to add a new web view:
Next, fill out the required information including a name for the web view, the address to the icon to use, and the website URL to the desired website to embed.
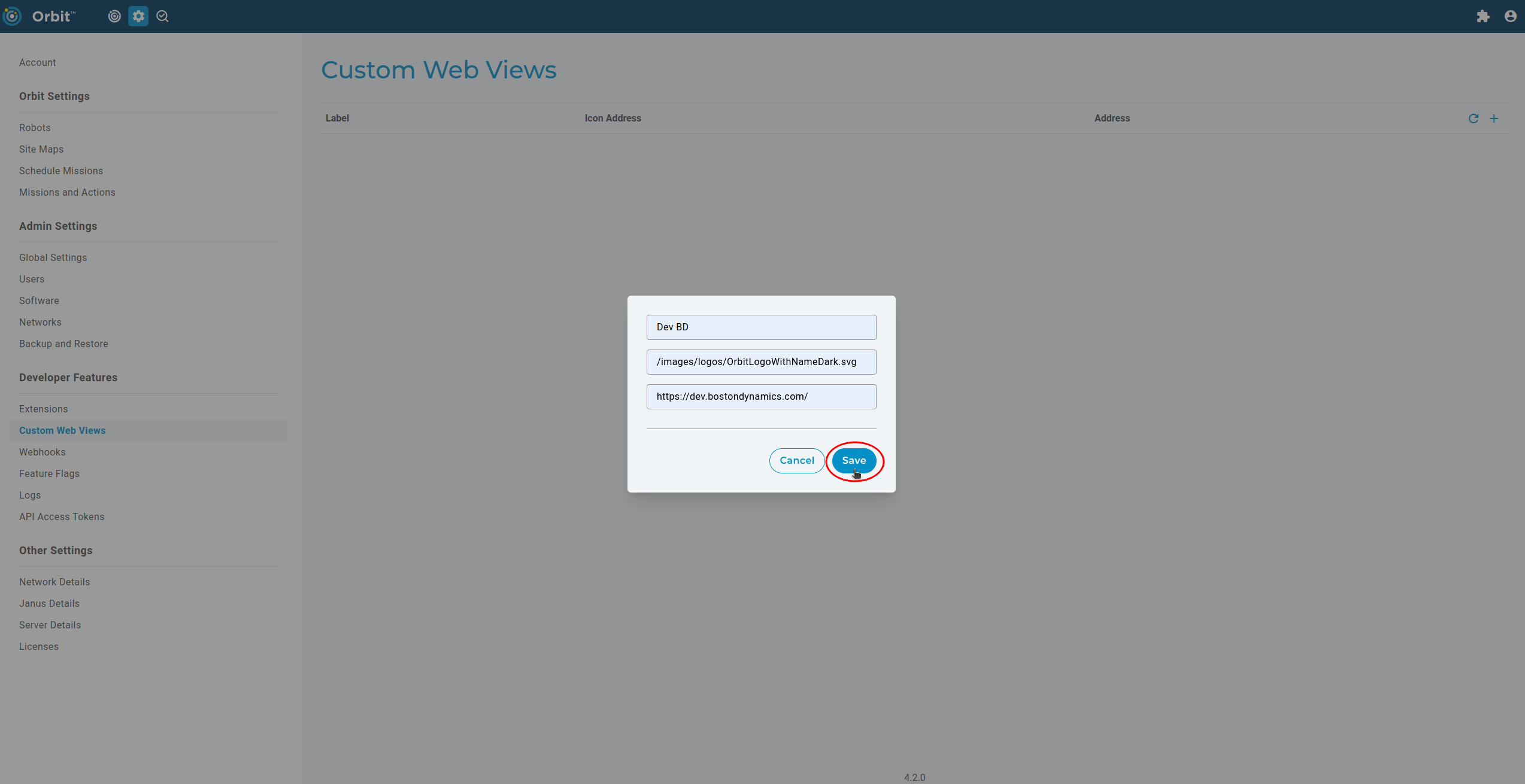
If done correctly, the web view should populate in the “Custom Web Views” button in the top right. Clicking on the web view should then show the content of the website within the Orbit UI as shown below.
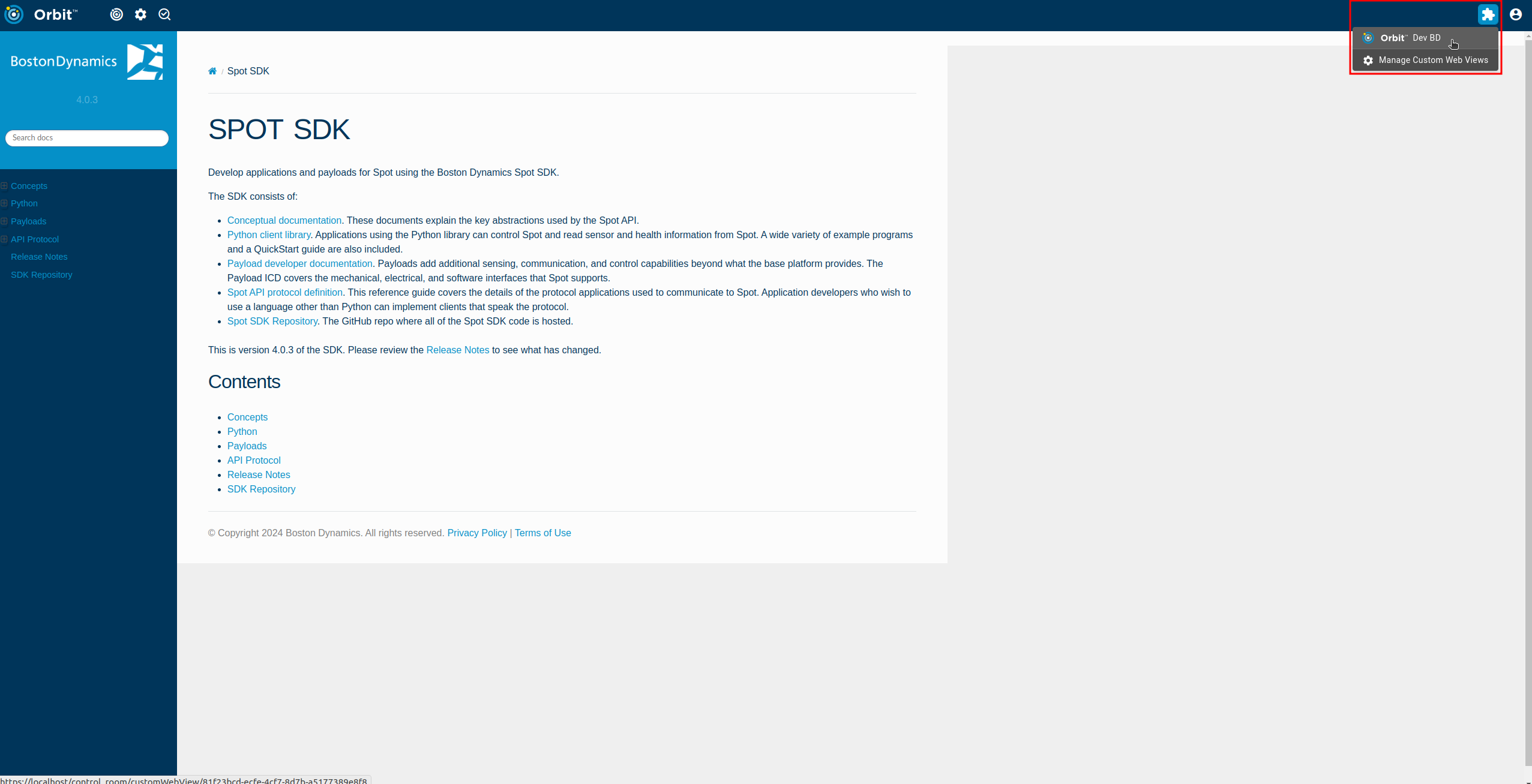
WebViews rely on the user’s browser for things like networking, cookies and caching. This means that clients interact with external websites independently and are able to access web views for websites that Orbit does not have proper routing to. In the example above, the Orbit instance is unable to curl https://dev.bostondynamics.com/ but the web view still works as intended on the client browser.
Custom WebViews
Developers can create and deploy web applications to Orbit using an Extension. The extension should serve the web application via HTTP on a port in the range 22101-22200. Orbit will proxy HTTPS requests on the port range 22001-22100 to the respective ports in the range 22101-22200. Clients should make requests to the range 22001-22100. Custom WebViews can be configured using this URL to present the extension’s web application within the Orbit application itself.
Note that the client requests are HTTPS. Orbit will use the same TLS certificate as the Orbit web application when proxying for the extension’s web application.
The port mapping is as follows:
| Frontend | Backend |
|---|---|
| 22001 | 22101 |
| 22002 | 22102 |
| ... | ... |
| 22100 | 22200 |
In production environments, it is recommended to use the following in the docker-compose.yml of the Orbit Extension to ensure that the HTTP server is not accessible by external clients:
...
ports:
- "127.0.0.1:<backend_port>:<backend_port>"
...
Extensions can also host web servers as an Orbit extension within the port ranges 21000-22000 that can then be pointed to as a web view, though the user will have to visit the direct URL, https://ORBIT_IP:PORT/, of the web server first to get around the privacy error described in the WebViews section. This port range does not support unencrypted HTTP servers as web views.
Note
Orbit does not save any credentials or payloads passed to external websites.
Webhooks
In addition to providing programmatic and on-demand access to data via the API, Orbit can also push data to applications via webhooks when an event occurs.
What is a webhook?
Most generally, a webhook is a mechanism by which one system sends real-time data to another system when an event occurs. In this case, Orbit is the event source. Its job is to identify when an event occurs, at which point it will send an HTTP POST request with data about the event to any webhooks registered and subscribed to that event.
Configuring Webhooks
Webhooks can be configured by an Orbit admin on the settings page or by a developer via the HTTP endpoints at https://my-orbit.com/api/v0/webhooks/. See the webhooks API documentation for more details on the webhooks endpoints.
For webhooks to work, Orbit needs to know where and when to send the data. When creating a webhook, a URL must be specified. This is the location of the target HTTP endpoint and will be called with a POST request when an event occurs. Additionally, Orbit requires a list of subscribed events for each webhook. When any one of these events occur, Orbit will send a request. See the section below for the list of supported events.
Webhook Payloads
When Orbit makes a request to a registered webhook, it includes information about the source event in the body of the request. The structure of the event payload is shown below.
{
// Unique identifier for this event.
uuid: string
// The type of event that was triggered.
type: string
// ISO date string indicating when event was triggered.
time: string
// Data about the triggered event. The structure will depend on the event type.
data: { ... }
}
Webhook Events
Orbit allows a webhook to subscribe to multiple events. The webhook will be invoked if any one of the events occur.
Action Completed
The “action completed” event is triggered whenever a robot completes an action. The value of type in the request payload will be "ACTION_COMPLETED". The structure of the data field will be identical to the run_event object. At a high level, it contains information about the completed action like the name of the action, when it occurred, any key results that were generated, as well as links to any images that were taken as part of the action. See the run_events API documentation for more details on the data contained in a run_event.
Action Completed With Alert
The “action completed with alert” event is triggered whenever a robot completes an action where anomalous data was collected. For example, if a thermal inspection identifies an object that is above the configured maximum temperature threshold, Orbit will trigger the “action completed with alert” event. The value of type in the request payload will be "ACTION_COMPLETED_WITH_ALERT". The structure of the data field will be identical to the run_event object. At a high level, it contains information about the completed action like the name of the action, when it occurred, any key results that were generated, as well as links to any images that were taken as part of the action. See the run_events API documentation for more details on the data contained in a run_event.
Securing Webhooks
Webhooks have a configurable secret property that is used for securing webhook payloads. The secret is a 64 character hex string used to sign each webhook request. The HTTP requests are sent with a Orbit-Signature header with the following format:
t=1701098596652,v1=<SIGNATURE>
The value of t in the header is the unix timestamp when the message was sent by Orbit. The value of v1 is the hash-based message authentication code (HMAC) generated by:
Creating a timestamped payload string of the form
<t>.<payload_json_as_string>Creating an HMAC using the webhook secret as the key, the timestamped payload string as the message, and the SHA256 hash function
Generating the hexadecimal representation of the HMAC. This hex string should match the value of
v1
The bosdyn-orbit module has a utility validate_webhook_payload that can be called from a webhook with the configured secret and the payload to handle these steps. This validation ensures that:
The payload came from Orbit.
The payload was not altered in transit by a man in the middle.
The payload was not replayed by a man in the middle.
HTTP vs HTTPS
Orbit supports the registration of endpoints using both http and https. Using http can be useful in certain development environments, but is strongly discouraged for production applications.
For https endpoints, by default, Orbit will validate the TLS certificate when establishing a connection to the server. Requests to servers with invalid certificates will fail. This can be overridden on the webhook configuration page or by setting validateTlsCert to false when creating a webhook through the REST API. Using unrecognized TLS certificates, like self-signed certs, can be useful during development but is strongly discouraged for production applications.
Should I use webhooks or the Orbit API?
Orbit webhooks and REST API are both equally valid mechanisms for integrating with data collected by a robot. The choice of which to use depends on what needs to be done with the data.
When to use the Orbit API
The Orbit API is better suited for integrations that require on-demand access to data. For example, maybe an application generates a report of data collected by Orbit during a custom time period. At the click of a button, the application returns a report of the relevant data. This use case is more easily achieved using the REST API since the application may request data as-needed (e.g., whenever the button is clicked).
When to use webhooks
Webhooks are great for integrations that require real-time data or applications that want to do something when a particular event occurs. For example, an application that creates a work order in an Enterprise Asset Management (EAM) system whenever the robot identifies an anomaly during an inspection. The application can host a webhook that subscribes to the "ACTION_COMPLETED_WITH_ALERT" event and sends the necessary data to the EAM system whenever the event is triggered.
Scheduling Missions
Orbit has built-in functionality for scheduling missions. Once scheduled, Orbit will kick off and monitor the mission automatically at the prescribed time. The system supports multiple schedules per robot, adjustable repeat configurations, launch windows, and other features described below.
Key Concepts
These concepts are the building blocks of the Orbit scheduling system.
Schedule: A schedule is a description of what a specific robot should do, when it should do it, and how often it should repeat the mission. For example, “Spot should run the mission called ‘Gauge Reading’ every day at 12:00pm”.
Event: Events are specific instances of a schedule. Taking the example above, if it is now Monday at 12:00pm, Orbit would start the event that results in Spot executing the Gauge Reading mission.
Start Time: The ideal time that an event will begin; “ideal” and not “actual” because many things could prevent the event from starting at the given time: a prior mission ran long, the robot is being teleoperated by a user, or there is a different schedule that takes priority - just to name a few. In the example above, the first start time is the timestamp of Monday at 12:00pm. The next start time will be automatically calculated once the event completes, and will be the original start time plus one day. This value will keep updating over time.
Repeat Interval: The ideal gap between event kickoffs. This has a practical minimum of 60 seconds and no maximum. To specify a schedule that does not repeat, provide a non-positive value in this field. It’s important to note that the repeat interval is relative to start time, not end time. The system tries to keep start times locked to real-world time as much as possible. Taking the example above, the repeat interval is set to one day (expressed as milliseconds). It’s possible that the robot will miss its start time, or be delayed in its mission and return late. In this case, the next start time is calculated to be Tuesday at 12:00pm, rather than Tuesday at 12:00pm plus the delay duration. This is to prevent a 12:00pm mission from creeping later and later and eventually running at midnight.
Blackout Times: Blackout times are blocks of time when a schedule will not start events, even if the start time is valid. Let’s modify the example case to be “Run the Gauge Reading mission every Monday, Wednesday, and Friday at 12:00pm”. To achieve this, simply add blackouts, while keeping the same repeat type and repeat interval, to prevent the schedule from running on opposite days. In this case, after the Monday event, the scheduler will still pick Tuesday at 12:00pm for its next start time, but once that time rolls around, it will not start the event because that time is in blackout. The customer-facing term for this is launch window, and it is the inverse of blackouts. Note that there are some corner cases here to be aware of, which are discussed below.
Weekly Repeat
The scheduler uses a week as its repeating unit, and Sunday as the first day of the week. That means that blackouts are specified as millisecond offsets since Sunday at midnight.
Predicting Start Times
As noted above, the system uses event start times, not end times. Keep the following in mind when planning schedules:
If the robot needs to be out of a particular area at a particular time, and it has a schedule and mission that traverses that area, the schedule should have a buffer between that time and the start time to allow the robot to complete its mission. For example, if the robot is not allowed to be near some of its inspection points at 11:00am, the last possible start time might be 10:00am to account for an estimated mission duration plus a buffer. Note that this can also be done with blackouts, but the buffer idea still applies.
The specified repeat interval is not guaranteed. The system prioritizes predictable start times over predictable intervals. For example, if a schedule has the repeat interval set to one hour, the system will try to start those events 60 minutes apart - it will not wait one hour after the robot returns. In this case, it’s possible that the robot starts a mission at 11:00am, returns at 11:55am, and starts the next event at 12:00pm, leaving only a 5 minute gap between mission completion and kickoff. This is intentional and by design.
If there are multiple schedules running for one robot, the schedules might interfere with each other. This is a normal and expected state to be in. The system will continue to start events according to their priority (described below), but predicting each event’s start time gets more difficult. If very predictable start times are required, it is recommended to configure the schedules such that it is unlikely that a long-running mission will disrupt the next schedule - for example, one schedule that runs between 8:00am and 10:00am and another that runs at 12:00pm.
Schedule Priority
As the number of robots and schedules increases, it is likely that multiple events will be eligible for dispatch at the same time - for example, a robot could have Schedule A that runs as fast as possible between 10:00am and 12:00pm, and Schedule B that runs once an hour between 9:00am and 5:00pm. For part of that duration, events from both schedules are allowed to run. This is how the system determines which one will actually be sent to the robot:
Run the “stalest” event first
In steady state, this is the event that ran furthest in the past. If Schedule A last ran fifteen minutes ago, and Schedule B last ran two minutes ago, Schedule A is staler, and a Schedule A event will be started.
If one of the two has never been run before, that one will be chosen. In the case of a tie, read on.
If two events are tied (most likely if they have been created at the same time), whichever mission’s name comes first alphabetically is chosen.
Scheduling “Gotchas”
The scheduler design has some side effects that are predictable, but worth shedding light on. If something strange is happening, one of the following situations may apply.
Missions Running at Midnight
If the scheduler misses a scheduled start time for any reason, it will try to dispatch the missed event at the earliest available opportunity. This can happen if the robot is late getting back from a prior mission. For example, suppose a schedule is set up to run an event at 12:00pm every Monday, Wednesday, and Friday. To accomplish this, the schedule must have blackout periods for Tuesday, Thursday, Saturday, and Sunday, from midnight to midnight. This scenario will play out as follows:
The robot runs its first mission on Monday at 12:00pm. The next start time is scheduled for 24 hours later, so Tuesday at 12:00pm.
Tuesday at 12:00pm rolls around, and the schedule is in a blackout period, so the event is not started.
The scheduler checks often (on the order of seconds) to see if it’s able to dispatch the overdue event.
The clock ticks over from 11:59pm on Tuesday to 12:00am on Wednesday. This is the first time since the missed event that the schedule is not in blackout, so the scheduler starts it now - at midnight on Wednesday.
If running the robot at midnight is undesirable, this may be avoided by extending the blackout until the next desired start time. That is to say, blackouts must be added not just on the alternate days, but also from midnight to 12:00pm on Monday, Wednesday, and Friday. The result of this is that Tuesday’s missed event is next valid on Wednesday at noon, not midnight.
Unpredictable “Fast as Possible” Schedules
An implicit race condition due to polling means that it is possible for an event to be passed over for dispatch in some cases. Ideally, three schedules (A, B, and C) should start events in a predictable order: A, B, C, A, B, C (recall the “stalest first” prioritization system). However, when scheduling with the API, a race condition could result in multiple “fast as possible” schedules dispatching in a non-deterministic order. In this case, set the repeat interval to be identical for all schedules. The recommended interval for “fast as possible” is 60 seconds (although it can be anything, as long as it is the same across all schedules).
Time Zones
The API expects Coordinated Universal Time (UTC) times. If the schedules run with an offset from the given times, check this.
Daylight Savings Time
The scheduler does not handle Daylight Savings Time yet. This is slated for a future release.
Work Orders
Orbit allows integration with external Work Order Management Systems (WOMS). When alerts occur in Orbit, work orders can be created manually from within the Orbit UI or automatically at the time of the alert.
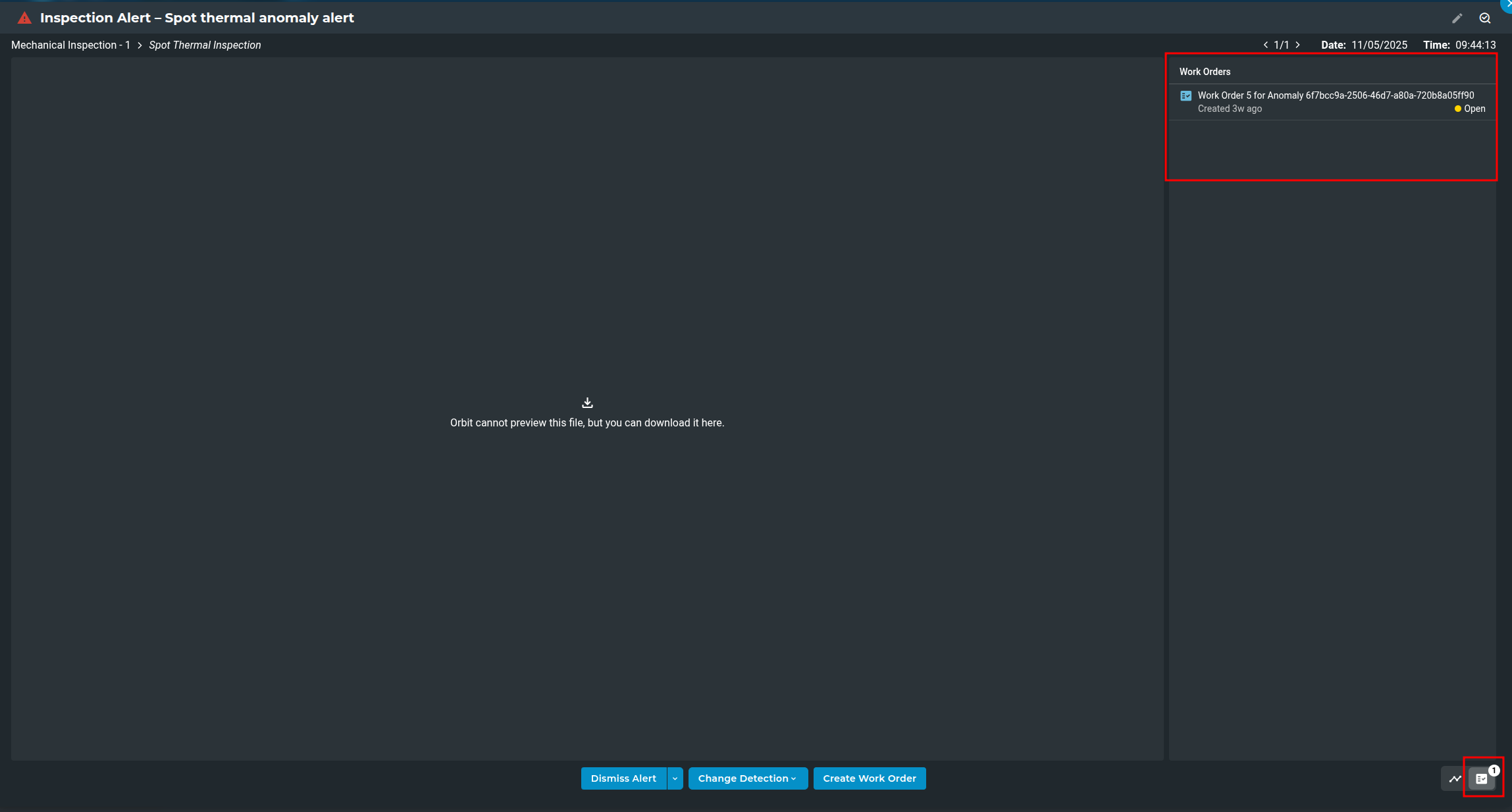
You can create a work order manually while viewing an Orbit alert:
How Orbit Integrates with Work Order Management Systems
When a creation request is made to the Work Order endpoint in the Orbit API, Orbit will send an HTTP POST request to a configured external endpoint with information about the work order to be created. The external system is then responsible for creating the work order in its own system. Orbit will map the external work order ID to the action that caused the alert for future reference. The status of the work order ID is automatically synchronized periodically in Orbit by querying the external system for updates. Changes in status may take time to reflect in Orbit depending on how many work orders Orbit is keeping track of.
Below is an example creation input that Orbit can support:
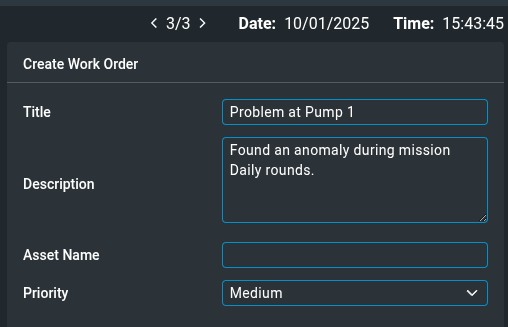
This input can be populated with information about the alert that caused the work order to be created, including images and key results collected during the action. See Configuring Work Order Integrations for more details.
Orbit’s work order support may not fit perfectly with your external work order system. If you need more granular control of how the HTTP calls to the external system are made, an intermediate layer can be used to act as a “middleman” between Orbit and the external system. This layer would receive work order creation and status requests from Orbit, translate them into the appropriate format for the external system, and send the requests on behalf of Orbit.
Configuring Work Order Integrations
Work orders are disabled by default, but can be enabled and configured by an Orbit admin on the settings page.
Creation
Work order creation allows Orbit to create work orders in an external work order management system when an alert occurs. To configure work order creation, the following fields must be configured (supported injection fields are listed in parentheses {}):
Create URL: The URL of the external endpoint that Orbit will send HTTP POST work order creation requests to.
Authentication Type: The HTTP header that contains the authentication information for the external system. For example,
Authorization: Bearer <token>.Work order spec: A JSON (in shape of
bosdyn.api.DictParamSpec) template that describes how to populate the work order creation request body. See the Work Order Specification section below for more details. {anomaly, images, user}Title field: The field in the external work order creation response that contains the work order title.
ID field: The field in the external work order creation response that contains the work order ID.
Detail URL: The URL to the detail page in the external system. {id}
Work Order Specification
The work order specification is a JSON (in shape of bosdyn.api.DictParamSpec) template that describes how to populate the work order creation request body. The structure of the template follows the service customization Spec pattern with the addition of templated insertion. The template can include static fields as well as dynamic fields that are populated with information about the alert that caused the work order to be created.
Templated Insertion
For dynamic fields, the following templated insertion objects are supported:
{anomaly}: The anomaly (alert) object that caused the work order to be created.{images}: If applicable, a list of jpegImageprotobuf messages with their bytes fields base64 encoded.{user}: If created manually, the user object that created the work order.
Below is an example of an anomaly object:
{
"uuid": "2ddf807b-cba3-4274-8e15-4902b803046e",
"name": "Pipeline Leak Detection Action",
"elementId": "6b167f7e-7912-45cf-bcb1-bb4b0ef63c01",
"assetId": "Pipeline Segment 42",
"customMetadataTags": ["inspection", "pipeline", "leak-detection"],
"time": "2025-07-31T21:38:52.312Z",
"runUuid": "778bb71e-5ba6-4d66-9725-6a0192d3fccd",
"runEventUuid": "b39fd6c9-b6fa-4a9d-8840-890399861f42",
"createdAt": "2025-09-30T21:26:29.292Z",
"status": "open",
"statusModifiedAt": "2025-09-30T21:26:29.292Z",
"statusModifiedBy": null,
"actionName": "Pipeline Leak Detection Action",
"missionName": "Pipeline Inspection Mission",
"channelName": "leak-detection-channel",
"dataCaptures": [
{
"time": "2025-07-31T21:38:52.312188+00:00",
"uuid": "4bdc55e8-ed82-46b9-b40f-83d73dddaed2",
"dataUrl": "/daq/download/...",
"createdAt": "2025-09-30T21:26:29.255377+00:00",
"keyResults": [
{ "name": "SPL At Source", "units": "dB", "value": 55.43461227416992 },
{ "name": "SNR Value", "value": 242 },
{ "name": "SNR Threshold", "value": 200 }
],
"channelName": "leak-source"
}
],
"title": "Leak detected",
"source": "",
"severity": 4
}
The templateValue field can be used to populate the initial value in the field. To inject the action name of the anomaly into a work order field, the following template may be used:
"title": {
"spec": {
"stringSpec": {
"editable": true,
"templateValue": "Problem found at {anomaly.actionName}"
}
},
"uiInfo": {
"displayName": "Title",
}
}
Example work order specification using templates:
{
"specs": {
"title": {
"spec": {
"stringSpec": {
"editable": true,
"templateValue": "Problem at {anomaly.actionName}"
}
},
"uiInfo": {
"displayName": "Title",
"displayOrder": "1"
}
},
"priority": {
"spec": {
"stringSpec": {
"options": ["Low", "Medium", "High", "Critical"],
"defaultValue": "Medium"
}
},
"uiInfo": {
"displayName": "Priority",
"displayOrder": "4"
}
},
"assetName": {
"spec": {
"stringSpec": {
"editable": true,
"templateValue": "{anomaly.assetId}"
}
},
"uiInfo": {
"displayName": "Asset Name",
"displayOrder": "3"
}
},
"description": {
"spec": {
"stringSpec": {
"editable": true,
"templateValue": "Found an anomaly during mission {anomaly.missionName}. See full anomaly here: \n\n{anomaly}",
"isMultiline": true
}
},
"uiInfo": {
"displayName": "Description",
"displayOrder": "2"
}
}
}
}
This specification would generate the following work order creation request body:
{
"title": "Problem at Pipeline Leak Detection Action",
"priority": "Medium",
"assetName": "Pipeline Segment 42",
"description": "Found an anomaly during mission Pipeline Inspection Mission. See full anomaly here: \n\n{...anomaly object...}"
}
If the external system supports receiving images as base64 encoded strings, the spec can inject image data directly into the request using a string field. When injecting images, the images template variable will be a list of bosdyn.api.Image objects with their bytes field base64 encoded. For example, to include the first image in the work order description, the following template may be used:
"image": {
"spec": {
"stringSpec": {
"editable": true,
"templateValue": "See image: {images[0].data}"
}
},
"uiInfo": {
"displayName": "Image base64 data",
}
}
If added to the above work order specification, the generated work order creation request body would look like this:
{
"title": "Problem at Pipeline Leak Detection Action",
"priority": "Medium",
"assetName": "Pipeline Segment 42",
"description": "Found an anomaly during mission Pipeline Inspection Mission. See full anomaly here: \n\n{...anomaly object...}",
"image": "/9j/4AAQSkZ..."
}
Note, depending on how the external work order system expects images to be sent, it may be necessary to include additional fields in the work order specification such as the image filename, MIME type or even a middleman to handle the image upload separately.
Note, only JPEG images are supported at this time.
Status Synchronization
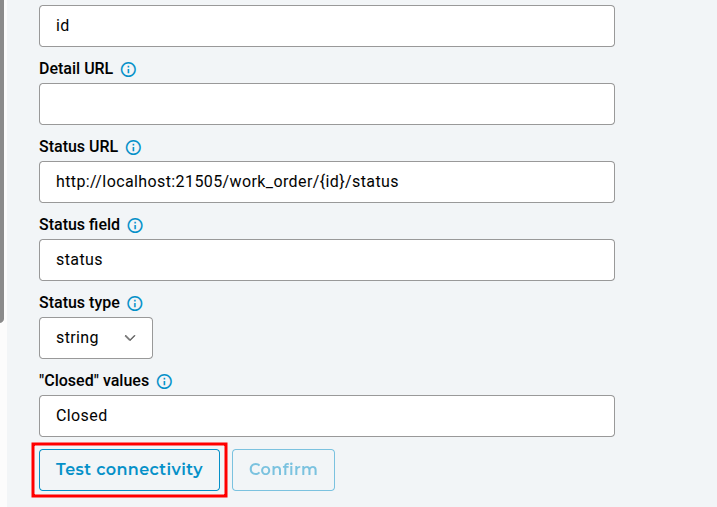
Work order status synchronization allows Orbit to periodically query the external work order system for updates on the status of work orders that were created from Orbit. To configure status synchronization, the following fields must be configured (supported injection fields are listed in parentheses {}):
Status URL: The URL of the external endpoint that Orbit will send HTTP GET work order status requests to. {id}
Status field: The field in the external work order status response that contains the work order status.
Status type: The type of status field returned by the external system. Supported types are
string,booleanandinteger.Closed value(s): The value(s) in the status field that indicate the work order is closed. Multiple values can be separated by commas. For example,
closed,resolved,completed.
Note, the status synchronization process runs periodically and can take longer to reflect changes in work order status depending on how many work orders Orbit is keeping track of.
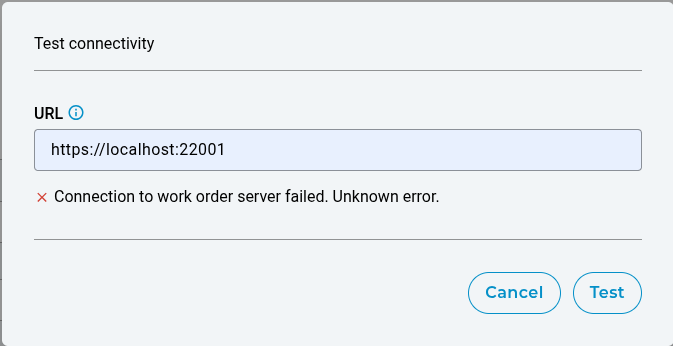
Integration Health
Orbit provides visibility into the health of the work order integration on the settings page. The health status indicates whether Orbit is successfully able to create work orders and synchronize their status with the external system. If there are any errors during these processes, Orbit will display the simple log output to assist in debugging.
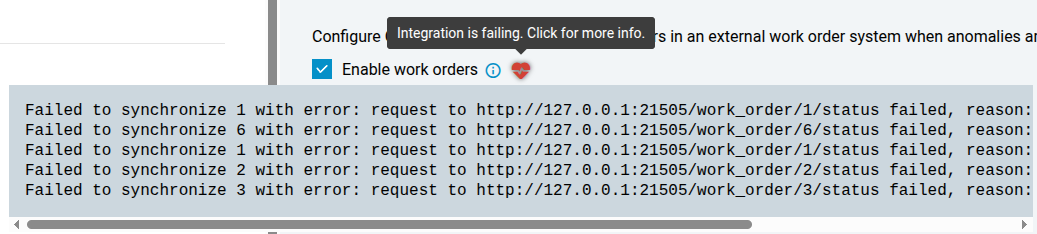
You can also test the connectivity of the work order integration by clicking the “Test connectivity” button. This attempts a GET request to the given URL to ensure a successful connection can be made.